- ChatGPT打不开,专用网络美国海外专线光纤:老张渠道八折优惠。立即试用>
- GPT3.5普通账号:美国 IP,手工注册,独享,新手入门必备,立即购买>
- GPT-4 Plus 代充升级:正规充值,包售后联系微信:ghj930213。下单后交付>
- OpenAI API Key 独享需求:小额度 GPT-4 API 有售,3.5 不限速。立即购买>
- OpenAI API Key 免费试用:搜索微信公众号:紫霞街老张,输入关键词『试用KEY』
本店稳定经营一年,价格低、服务好,售后无忧,下单后立即获得账号,自助下单 24小时发货。加V:ghj930213
立即购买 ChatGPT 成品号/OpenAI API Key>>
请点击,自助下单,即时自动发卡↑↑↑
OpenAI Embeddings 简介
什么是 OpenAI Embeddings
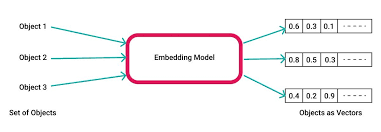
- OpenAI Embeddings 是一种将文本转换为向量表示的技术。它通过对大量文本数据的学习和分析,为每个文本字符串生成一个独特的向量。例如,text-embedding-ada-002 就是一个常用的嵌入模型 ID。将文本与特定的嵌入模型 ID 一起发送到嵌入 API 端点,就能得到相应的嵌入向量。这些嵌入向量可以被提取、保存和使用,在各种应用场景中发挥作用。比如在自建知识库中,通过将文本转化为嵌入向量,搭配 OpenAI 的问答系统可以根据用户提问从知识库中智能查找相关信息并回答。
- 它在很多场景中都有具体表现,如在文本分类中,可以利用嵌入向量对文本进行分类;在信息检索中,通过嵌入向量的相似性来查找相关文本;在语义相似性检测中,比较嵌入向量的相似度来判断文本的相似程度。
OpenAI Embeddings 的主要特点
- 具有高准确性,能够精确地捕捉文本的语义信息,这使得其在处理复杂的自然语言任务时表现出色。同时还具备灵活性,能够适应不同的应用需求和场景。
- 高准确性让其在需要精确理解和处理文本的场景中如鱼得水,比如在智能客服中能更准确地理解用户问题并提供准确答案。灵活性则体现在它可以与不同的技术和系统集成,比如可以与向量数据存储结合,即使存储限制为最高 1024 维嵌入,也能使用最好的嵌入模型 text-embedding-3-large 并指定合适的参数。另外,它和 OpenAPI UI 一起为 NLP 研究人员和开发者提供了强大的工具,帮助他们更好地进行自然语言处理工作。
OpenAI Embeddings 的相关信息
| 日期 | 相关内容 |
|---|---|
| 2023 年 5 月 6 日 | 主要介绍 OpenAI 的 Embeddings 接口,该接口可轻松执行自然语言和代码任务,如语义搜索、聚类、主题建模和分类 |
| 2023 年 5 月 21 日 | 在自建知识库中应用,通过将文本转化为嵌入向量形式,搭配 OpenAI 问答系统可根据用户提问从自建知识库中智能查找相关信息并回答 |
| 2023 年 12 月 16 日 | 介绍使用 OpenAI API 创建文本嵌入的指南,以及在文本分类、信息检索和语义相似性检测等中的应用 |
| 2024 年 1 月 29 日 | 介绍这一技术应用的灵活性,如在特定场景下对嵌入模型的使用 |
| 2024 年 2 月 29 日 | 说明获得嵌入模式的方法和嵌入模式的具体形式 |
OpenAI Embeddings 的使用方法
获取嵌入的步骤
- 发送文本和选择模型 ID: 要获取嵌入,需将文本字符串发送到 embeddings API 端点,并同时选择嵌入模型 ID(如 text-embedding-ada-002)。
- 嵌入的提取、保存和使用: 响应中会包含嵌入,我们可以从中提取并进行保存,然后在各种应用场景中加以使用。
不同场景下的使用
- 自建知识库: 在自建知识库中,通过把文本转化为嵌入向量形式,结合 OpenAI 的问答系统,能根据用户提问从自建知识库中智能查找相关信息并给出回答。比如,我们可以构建一个关于历史知识的自建知识库,当用户询问某个历史事件时,系统能快速准确地找到相关信息并反馈。
- 文档问答: 可以利用 OpenAI Embedding 进行文档问答,了解其工程化的难点与步骤等。例如,在处理大量文档时,通过嵌入技术能快速找到与问题相关的文档片段进行回答。
- 搜索: 在搜索场景中,利用 OpenAI Embedding 可以提高搜索的准确性和相关性,能更精准地找到符合用户需求的内容。
- 分类: 例如使用 Embeddings 文本分类方法,通过词嵌入技术对文本进行表示,然后基于此进行分类,如将新闻文章按主题分类等。
其他相关信息
我们还可以参考ChatGPT VPN 无法使用的解决办法(chatgpt vpn 无法使用)来获取更多有价值的内容。此外,还可以深入了解 OpenAI 的 Embeddings 接口,它能够轻松执行自然语言和代码任务,如语义搜索、聚类、主题建模和分类等。通过不断学习和实践,我们能更好地掌握和运用 OpenAI Embeddings。

OpenAI Embeddings 的工程化详解
工程化的要点
- 如何进行工程化: 首先要明确如何将 OpenAI Embeddings 实际应用到项目中。这包括将文本数据转化为嵌入向量,选择合适的嵌入模型等操作。同时还需注意数据的预处理、模型的参数设置等要点。
- 工程化的难点: 难点可能在于处理大规模数据时的效率问题,以及如何确保嵌入向量的准确性和可靠性。解决这些难点需要采用合适的技术和算法,如数据并行处理、模型优化等。
应用实例分析
- 实际案例展示: 以文档问答系统为例,详细介绍如何利用 OpenAI Embedding 实现该功能。首先将文档转化为嵌入向量,然后根据用户提问生成对应的嵌入向量,通过比较两者的相似性来查找相关答案。
- 工程化优势和成果: 在这个过程中,工程化的优势体现在能够快速、准确地处理大量文档和问题,提供高质量的问答服务。成果可以是提高了问答系统的效率和准确性,提升了用户体验。
关于 OpenAI Embedding 的更多知识
- OpenAI 的嵌入是归一化到长度为 1 的,这意味着使用点积可以更快地计算余弦相似度,余弦相似度和欧几里得距离将得到相同的排名。
- 要获得嵌入,需将文本字符串发送到 embeddings API 端点,同时选择嵌入模型 ID(如 text-embedding-ada-002),响应将包含嵌入,可提取、保存和使用。
- Embedding 就是用一个数值向量“表示”一个对象的方法,“实体对象”可以是 image、word 等,“数值化表示”就是一个编码向量。比如对“颜色”这种实体也可以这样表示。
OpenAI Embedding 在自建知识库中的应用
| 应用场景 | 具体描述 |
|---|

