- ChatGPT打不开,专用网络美国海外专线光纤:老张渠道八折优惠。立即试用>
- GPT3.5普通账号:美国 IP,手工注册,独享,新手入门必备,立即购买>
- GPT-4 Plus 代充升级:正规充值,包售后联系微信:ghj930213。下单后交付>
- OpenAI API Key 独享需求:小额度 GPT-4 API 有售,3.5 不限速。立即购买>
- OpenAI API Key 免费试用:搜索微信公众号:紫霞街老张,输入关键词『试用KEY』
本店稳定经营一年,价格低、服务好,售后无忧,下单后立即获得账号,自助下单 24小时发货。加V:ghj930213
立即购买 ChatGPT 成品号/OpenAI API Key>>
请点击,自助下单,即时自动发卡↑↑↑
了解CartPole-v1环境
在强化学习中,了解和熟悉不同环境是至关重要的。CartPole-v1环境是一个经典的强化学习环境,通过模拟一个平衡杆(pole)放置在移动小车(cart)上的情景,旨在让智能体学会通过左右移动小车来保持杆的平衡。下面让我们深入了解CartPole-v1环境的基本设置和具体任务,以及它在强化学习中的作用。
CartPole-v1环境的基本设置:
- CartPole-v1环境是一个2D模拟环境,包括一个移动小车和一个平衡杆。
- 智能体可以通过施加力来左右移动小车,以尽可能保持平衡杆的垂直。
- 环境会返回+1的reward作为奖励,用于指示智能体是否在任务中表现良好。
CartPole-v1环境的具体任务:
CartPole-v1环境的任务是让智能体学会控制移动小车,以防止平衡杆倾倒。通过在每个时间步中选择合适的动作,智能体需要尽可能长时间地保持平衡杆在垂直位置,以获得最大的累积奖励。当平衡杆倾斜角度过大或者小车移动超出边界时,游戏将结束。
CartPole-v1在强化学习中的作用:
CartPole-v1环境作为一个简单而经典的强化学习环境,具有以下重要作用:
- 教学示范:CartPole-v1环境可以作为教学示范,帮助初学者理解强化学习的基本原理和方法。
- 算法验证:研究人员可以利用CartPole-v1环境验证各种强化学习算法的效果和性能。
- 参数调优:通过调整智能体的学习速度、动作选择策略等参数,可以在CartPole-v1环境中进行参数调优实验。
通过深入研究和实践CartPole-v1环境,我们可以更好地理解强化学习的核心概念,并为更复杂的任务和环境设计更有效的智能体和算法。
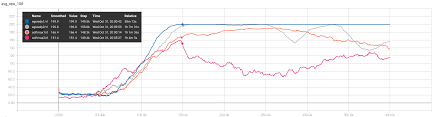
使用Q学习玩CartPole-v1
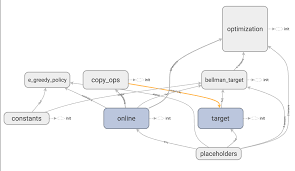
在强化学习领域,Q学习是一种经典的算法,被广泛应用于解决各种控制问题。让我们深入了解Q学习的基本原理以及在CartPole-v1环境中的应用。
Q学习算法简介
- Q学习的基本原理
- Q值函数在强化学习中的作用
Q学习是一种基于值函数的强化学习算法,它通过学习Q值函数来指导Agent做出具体动作,以最大化长期奖励。在每个状态下,Agent会根据当前的Q值选择最优的动作,从而逐步优化策略。
Q值函数表示在当前状态下采取某个动作所能获得的长期奖励期望,是Q学习算法的核心。Agent会根据当前状态下的Q值来做出动作选择,通过不断更新Q值函数来获取最优策略。
Q学习在解决CartPole-v1环境中的应用
- 如何构建Q学习模型
- 训练Q学习模型的关键步骤
在CartPole-v1环境中,我们可以构建一个Q学习模型,通过Agent和环境的交互来学习最优策略。Agent会在每个状态下选择最优动作,并根据奖励信号不断更新Q值函数。
Q学习模型的训练包括初始化Q值函数、选择动作、获取奖励、更新Q值等步骤。通过多次与环境的交互,Agent能够学习到在CartPole-v1环境中保持杆子平衡的最佳策略。
在探索强化学习的世界中,理解Q学习算法的原理和应用是至关重要的。通过在CartPole-v1环境中实践,我们可以更深入地领会Q学习在实际问题中的应用和效果。想了解更多关于强化学习和人工智能的知识,可以查阅ChatGPT 4.0付费使用攻略。
探索OpenAI Gym的使用
OpenAI Gym是一个强化学习的标准工具包,为研究人员提供了丰富的仿真环境和数据,让他们能够更好地比较和评估强化学习算法的性能。下面我们将深入探讨OpenAI Gym及其在强化学习中的作用和应用。
OpenAI Gym的概述
- 什么是OpenAI Gym:
- OpenAI Gym在强化学习中的地位:
OpenAI Gym是由OpenAI开发的一个开源工具包,用于创建、测试和比较各种强化学习算法。它包含了众多经典的仿真环境,如CartPole和MountainCar等,帮助研究人员在标准化的环境下进行算法的验证和比较。
作为强化学习领域的标准工具包,OpenAI Gym为研究人员提供了一个统一的平台,使他们能够快速、方便地测试和比较各种算法的性能。通过在不同环境下的实验,研究人员可以深入了解算法在不同场景下的表现,并进一步改进和优化算法。
其他开放AI环境的探索
- 除CartPole-v1外的其他AI环境介绍:
- 不同AI环境对算法的要求与挑战:
除了CartPole-v1这个经典环境外,OpenAI Gym还提供了许多其他有趣的仿真环境,如Atari、Pong和FrozenLake等。每个环境都具有不同的特点和挑战,需要不同的算法来解决。
不同的AI环境对算法的要求和挑战各不相同。一些环境可能需要更加复杂的算法来解决,而另一些环境可能更侧重于算法的速度和稳定性。研究人员可以通过在不同环境下的实验,深入了解算法的适用性和性能。

未来的AI探索
在未来的人工智能(AI)领域,深度学习强化学习算法将扮演着至关重要的角色。这种算法与传统的强化学习有着明显的区别,通过深度学习的方式可以更好地理解和利用复杂数据,从而实现更高效的决策和行为控制。
未来,深度强化学习的发展方向将主要集中在以下几个方面:
- 对算法性能的进一步优化,提升智能体在复杂环境下的学习效率和准确性。
- 结合神经科学理论,模拟人类学习行为,实现更加智能化的决策过程。
- 探索多智能体系统,实现多智能体之间的协作与竞争,拓展人工智能在更广泛领域的应用。
强化学习的基本概念和工作原理
强化学习是一种通过智能体与环境的交互学习的方法,通过尝试和错误来实现最优决策策略。在这个过程中,智能体会根据环境的反馈调整自身行为,以获得最大化的长期奖励。
- 奖励函数:强化学习中的奖励函数用来评估智能体在特定状态下的表现,是智能体学习的反馈机制。
- Q-learning算法:Q-learning是一种基于值函数的强化学习算法,通过不断更新状态-动作值函数Q值来实现最优策略选择。
- 探索与利用的平衡:在强化学习中,探索新的状态和行为是很重要的,但也需要适当地利用已有的知识来提高学习效率。
AI在未来的应用前景
人工智能技术在各领域的应用前景广泛,未来的发展将带来更多突破和变革。
- 医疗领域:AI技术可以辅助医生进行疾病诊断和治疗规划,提高医疗效率和精准度。
- 智能交通:人工智能可以优化交通流量、自动驾驶技术的发展将改变出行方式,提升交通安全与效率。
- 金融领域:AI可以帮助金融机构进行风险控制、信用评估和投资决策,推动金融行业的创新。
| AI技术应用领域 | 前景展望 |
|---|---|
| 医疗健康 | 提高医疗效率,个性化治疗方案,辅助医生决策 |
| 智能交通 | 优化交通流量,推动自动驾驶技术发展,提升出行安全与便利 |
| 金融科技 | 风险控制与投资决策,创新金融服务模式 |
openai gym cartpole的常见问答Q&A
什么是OpenAI Gym的Cart Pole环境?
OpenAI Gym的Cart Pole环境是一个经典的强化学习环境,用于测试和开发强化学习算法。
- Cart Pole环境包含一个小车(cart)和一个杆子(pole),目标是控制小车平衡杆子使其不倒。
- 该环境是一个理想的起点,用于学习强化学习的基本概念和方法。
- Cart Pole环境的代码在OpenAI Gym中可用,并提供了一种标准化的问题来测试算法性能。
如何解决OpenAI的CartPole问题?
要解决OpenAI的CartPole问题,需要进行以下步骤:
- 建立控制模型,例如使用Q-Learning算法。
- 训练Agent,使其在游戏中保持杆子平衡。
- 评估性能,确保Agent在环境中表现良好并达到预期的目标。
如何使用Deep Q-Learning解决OpenAI Gym的CartPole问题?
要使用Deep Q-Learning解决OpenAI Gym的CartPole问题,可以按照以下步骤进行:
- 建立一个深度神经网络,用于学习通过强化学习玩游戏。
- 使用深度Q学习训练智能体玩CartPole游戏。
- 通过经验回放等技术不断优化模型,以更好地解决CartPole问题。
如何在OpenAI Gym中使用Cart Pole环境进行倒立摆控制?
要在OpenAI Gym中使用Cart Pole环境进行倒立摆控制,可以参考以下方法:
- 选择加载Cart Pole环境,创建一个让杆子保持平衡的问题。
- 初始化环境并返回初始状态,使用环境提供的函数进行交互。
- 运行训练和测试代码,优化控制策略,使小车平衡杆子并取得成功。